呢個視頻係我理解嘅源泉,如果我說嘅話有咩唔啱嘅,都以下面個視頻為主,唔好聽我的:
Base Model
生成图片的基础模型,如Stable Diffusion v1.5和v2.0和Pony。
Checkpoint
在深度学习中,Checkpoint可以理解为经过fine-tuning后的模型,是在基础模型的基础上微调得到的。这个过程能够生成更高质量的图片。通常,开发者会选择一个基础模型,然后在这个模型的基础上进行fine-tuning,调整模型的参数,使之适应新的任务或数据集。
在Stable Diffusion中,开发者会选择一个基础模型,然后通过fine-tuning调整模型的参数,以生成更高质量的图片。得到的这个经过fine-tuning的模型就称为Checkpoint。
为了获得Checkpoint,需要提供大量高质量的图片数据集进行训练。在训练过程中,模型会不断调整参数,尽可能地适应数据集,这就是fine-tuning的过程。
简而言之,Checkpoint是经过fine-tuning后基础模型的升级版,能够生成更高质量的图片。
類型
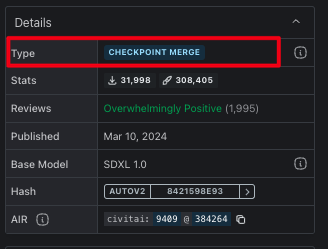
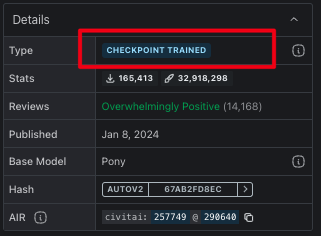
分为CHECKPOINT TRAINED以及CHECKPOINT MERGE,分别是别人训练好的和融合好的,它是大型模型,里面集合了模型参数、权重等,因此出图的的风格、画风已经相对固定。
好处就是可以直接拿来用,缺点就是想要再去微调十分麻烦,于是有了后面的lora、embedding等模型。这些属于附加模型,应用在checkpoint模型上,可以轻易对其进行微调,而且容易训练,十分方便。
Optional Model
如Lora和Texture Inversion,等模型可以被看作是在基础模型同埋Checkpoint基础上,生成的图片增加了一些额外的效果,以增强或改变图片的风格。
这些可选模型也需要进行训练才能得到。它们的作用是在不修改Stable Diffusion(SD)模型的基础上,定制SD模型的生成风格或添加新的人物/知识产权(IP)。
比如,如果我们想要生成一系列具有某种特定风格的图片,例如水彩画风格、卡通风格或者古典油画风格,我们可以训练一个特定的模型,比如Lora模型,来实现这个目标。这个模型就会在SD模型生成的图片上添加相应的效果,使得生成的图片符合我们想要的风格。
同样地,如果我们想要在生成的图片中加入某个特定的人物或知识产权(比如漫画中的角色、电影中的场景等),我们可以训练一个特定的模型来实现这个目标。这个模型会根据给定的人物或IP的特征,在SD模型生成的图片中添加对应的内容。
总之,这些可选模型通过训练来定制Stable Diffusion模型的生成效果,而不需要修改SD模型本身。
Inpainting Model(VAE)
修补模型(Inpainting Model)是用于修复图片中的某些部分的模型,例如修复人脸图片中的眼睛,或者可以理解为一种滤镜。这些修补模型依赖于训练。
Stable Diffusion框架可以被看作是一个“容器”,其中基础模型是这个容器的基石。其他模型和修补模型相当于可以自由拼接的“模块”,它们实现了不同的图片生成效果。但无论如何拼接,都需要基础模型作为生成图片的基础。
比如说,我们可以在基础模型上添加一个修补模型,用来修复图片中的缺失部分。这个修补模型可以是一个基于变分自动编码器(VAE)的模型,它会尝试预测缺失部分的像素,并用合适的内容填充。这样,我们就可以得到一张完整的图片,即使它的某些部分原本是缺失的。
LoRA
什麼是LoRA
LoRA,即低秩适应模型,它的核心思想是在不大改变原有模型结构的情况下,通过添加一些简化的额外矩阵来调整模型的权重,从而提升模型的性能或适应性。
簡單解釋
假设你有一辆车,可以满足你日常的通勤需求。但有一天,你要参加越野赛车比赛,你知道原车无法胜任这个任务,但你又不想换车。这时,你可以对车进行一些改装,比如换上越野轮胎、增强悬挂系统,这样车就能适应越野赛的环境。
在这个例子中,你的原车就像是一个已经训练好的神经网络模型,大多数情况下能很好地工作。但面对新的或特殊的任务(比如越野赛),它可能需要一些调整才能适应。LoRA模型的作用就像是对车进行的这些特定改装。通过在原模型上添加简化的额外部分,我们可以使模型更好地适应新的任务,而不需要重新设计或训练一个新模型。
这样做的好处是,与全面重新训练一个模型相比,LoRA模型的参数训练量少很多,也对硬件性能要求低很多,就像对车进行小改装就能应对新场景一样。
Embeddings
什麼是Embeddings
Embeddings,中文翻译就是“嵌入”,在深度学习里面通常是指一种高维空间中的点,它能够代表输入数据的关键特征,比如文本或者图像。
簡單解釋
Embeddings就像一个图鉴,帮助电脑理解各种事物。比如,我们想让电脑认识熊猫,我们会用词语“黑白相间的毛发”、“圆圆的脸”、“大大的黑眼圈”等来描述。这些描述就是熊猫的嵌入,把它们转换成了一组数字,这组数字包含了熊猫的关键特征。即使电脑以前没有见过熊猫,通过这些数字,它也能理解熊猫是什么样子。
Embeddings只是一种转换方法,它不能直接参与到繪畫或者其他操作里面。所以,它不能改变模型的权重参数,只能用来固定元素或者画面特征。这也是它的局限性。
Hypernetwork
什麼是Hypernetwork
在传统的神经网络中,权重是通过随机初始化或者经过训练学习得到的。但是,如果我们想要设计一个具有特定结构或者功能的神经网络,可能需要手动调整权重,这是一项繁琐的任务。
Hypernetwork的想法是让另一个神经网络来生成这些权重。这个生成权重的神经网络就是Hypernetwork。而那个需要权重的神经网络就是目标网络。
簡單解釋
假设我们要画一张图,但我们想要用一种特别的方式画。传统上,我们可能会手动选取颜色和笔刷来完成这个任务,但这可能会很耗时。
现在,我们有一个“画图机器”,它会根据我们给它的指示自动画图。但是,我们并不直接告诉机器每个像素应该是什么颜色,而是通过另外一个小机器来帮我们做这个任务。
这个小机器就是我们的“画图小助手”,我们给它输入一些简单的指示,比如“画一张太阳”,然后它会自动确定每个像素点的颜色和位置。
在这个例子中,画图机器就是我们的目标网络,而画图小助手就是Hypernetwork。Hypernetwork接受我们的指示(输入),然后生成出画图机器所需的具体指令(权重),从而帮助我们完成画图任务。这样,我们只需改变指示,就可以画出不同风格的图,而不必手动调整每一个像素。
(其實而家幾乎都冇人用這個生成LoRa取代咗)
用法
簡單說一下用法先。
civitai去找一個鍾意的模型,跟住進入頁面會看到好多的描述
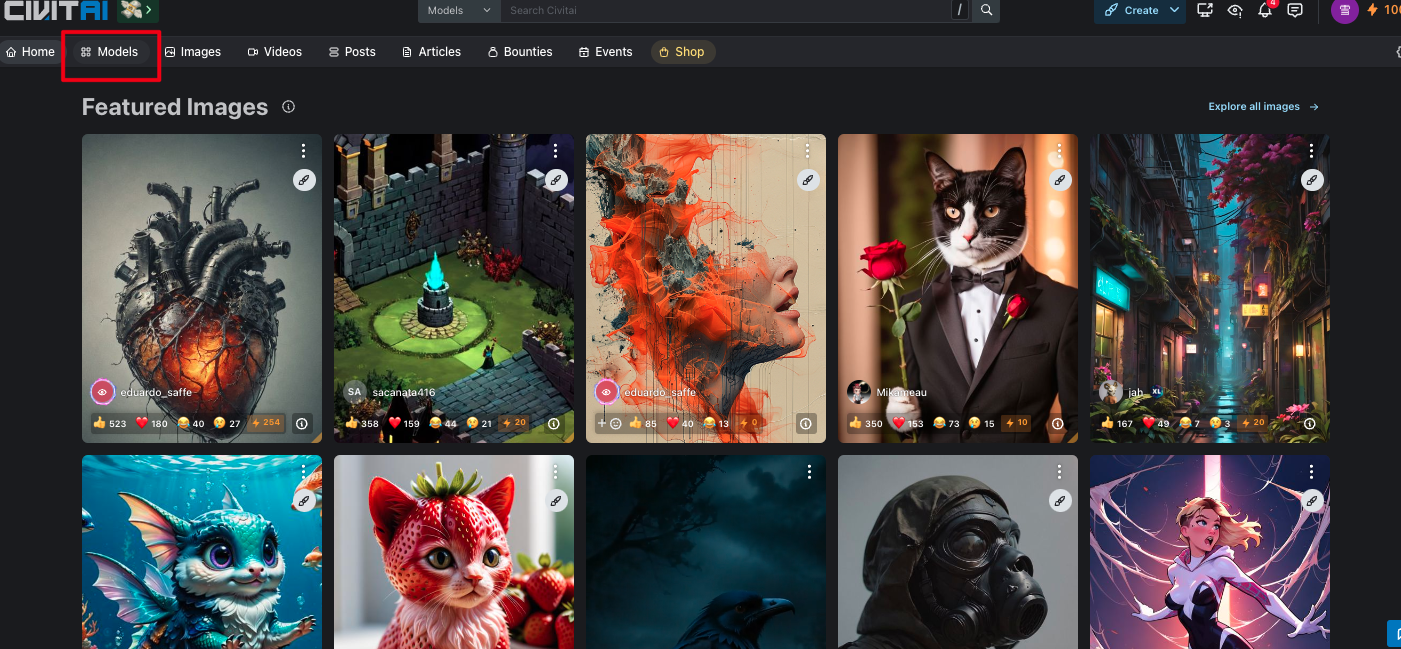
這裏可以找模型類型,下載想要的Base Modal,如果係都要再簡單點說的話,CheckPoint(train or merged)可以理解成同Base Modal是一個東西。
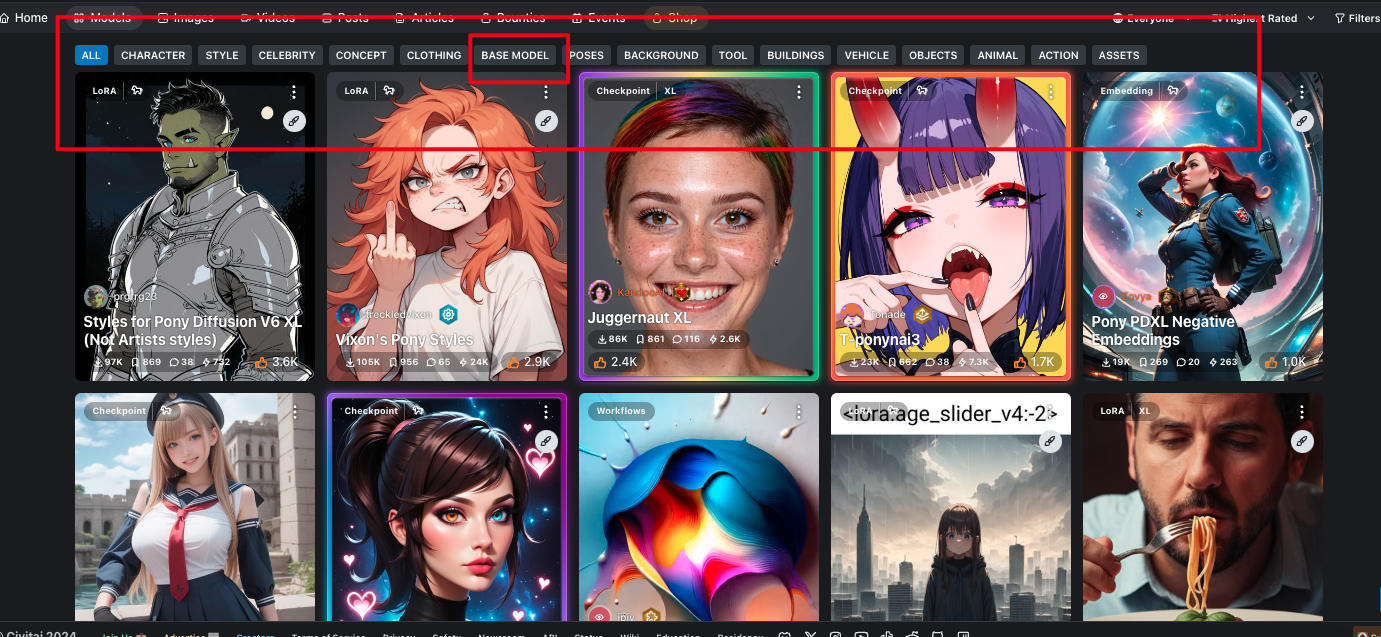
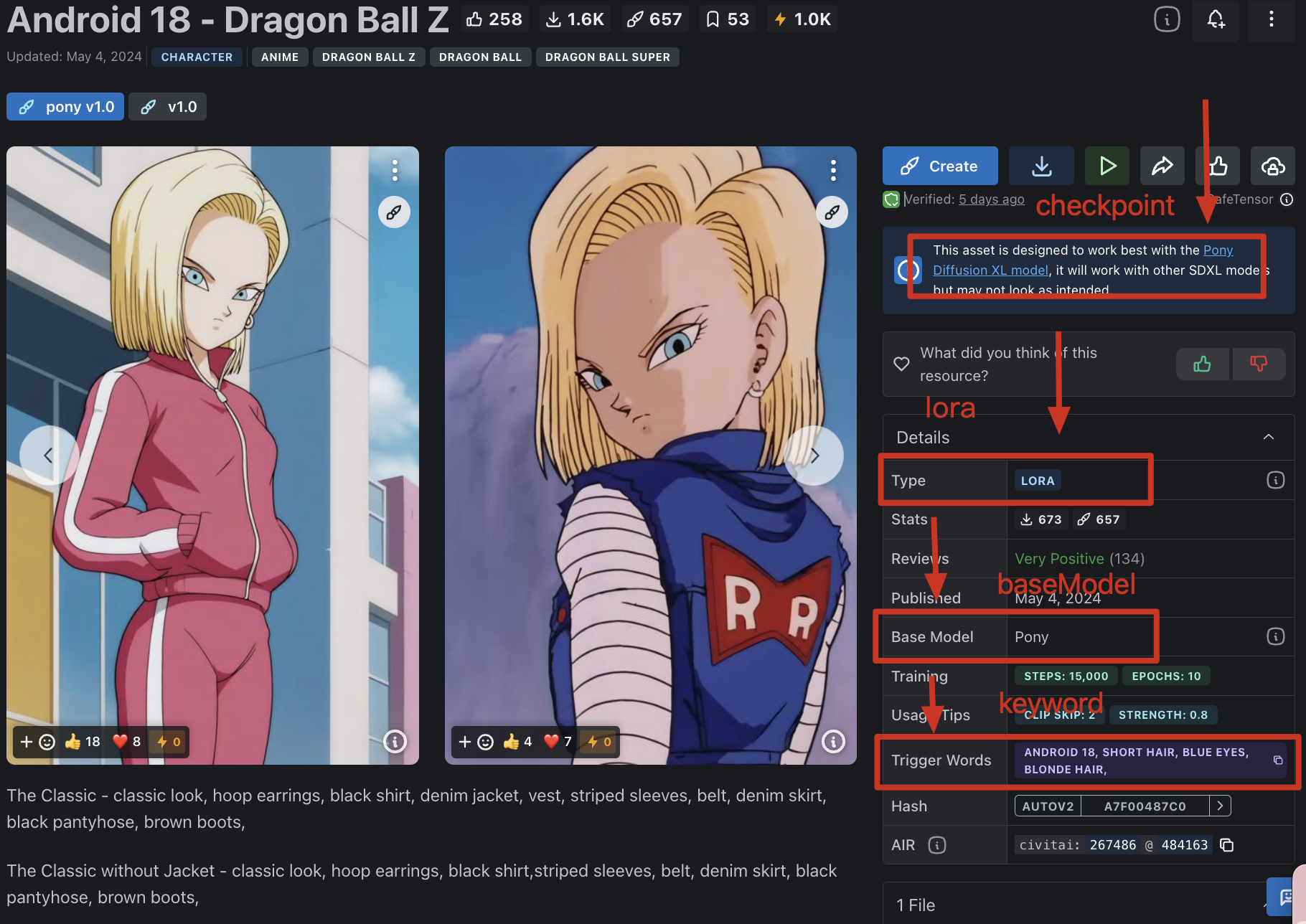
噉就知道需要下載啲咩模型,同埋擺係啲咩文件夾入便喇。
好多文章都介紹咗點將不同的模型放在不同的文件夾中,我之後有時間都會寫完這些內容。
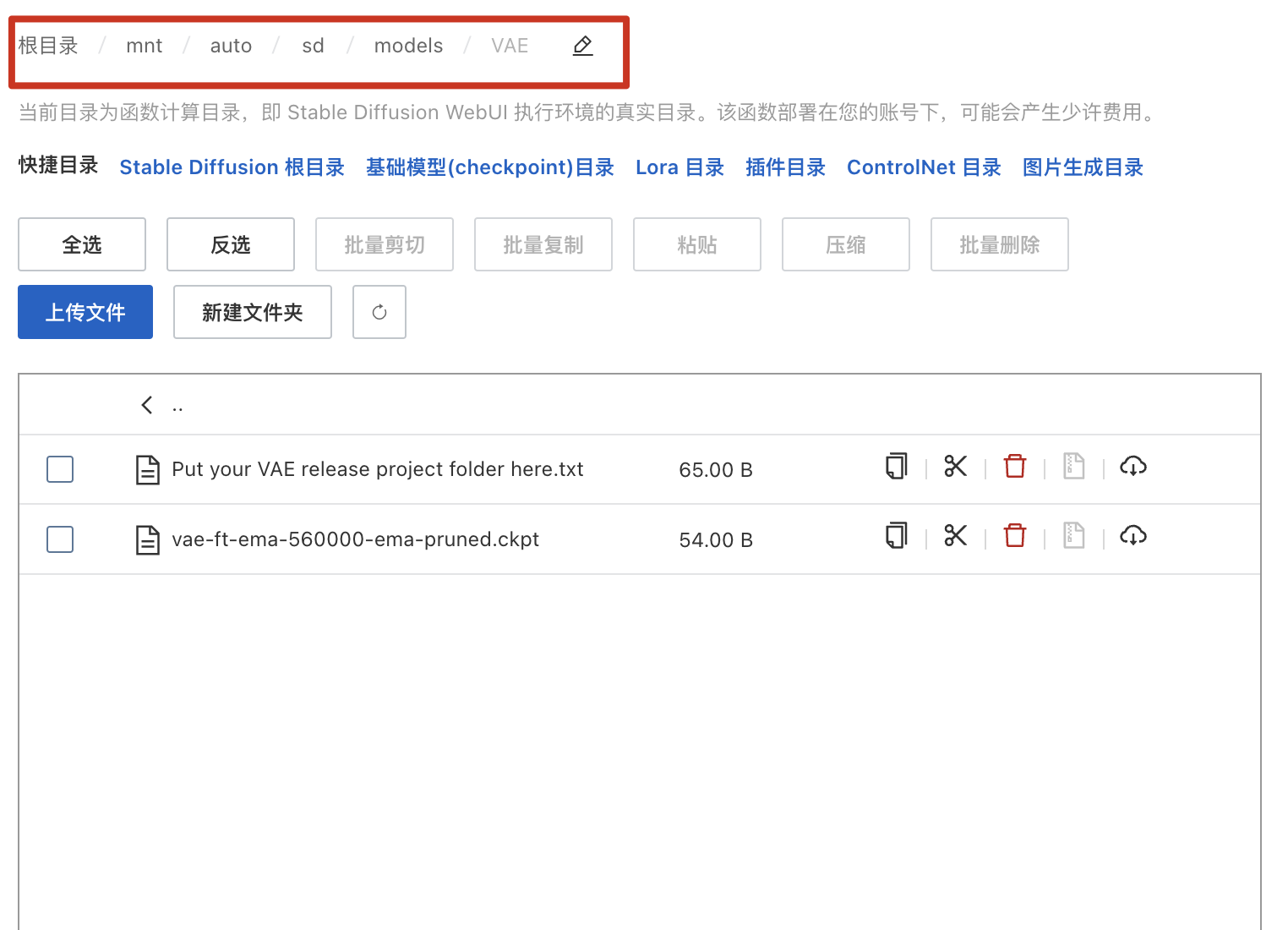
其實如果同我一樣都係部署(bou6 cyu5)係雲端嘅話,可以看到目錄(muk luk6)比如:
Base Model 目錄:

阿裏雲都幾完整嘅,除(ceoi4)咗VAE目錄冇寫,其他常用都寫埋tim。
同本地係一樣嘅,所有model都放係/mnt/auto/sd/models下,VAE都不例外